Reinforcement Learning With Dual-Observation for General Video Game Playing
Chengpeng Hu1, Ziqi Wang1, Tianye Shu1, Hao Tong1,2,
Julian Togelius3, Xin Yao1,2 and Jialin Liu1
1 Southern University of Science and Technology, China
2 University of Birmingham, UK
3 New York University, USA
IEEE TRANSACTIONS ON GAMES, VOL. 15, NO. 2, JUNE 2023 [IEEE] [Arvix]
Abstract
Transformed Game Observations
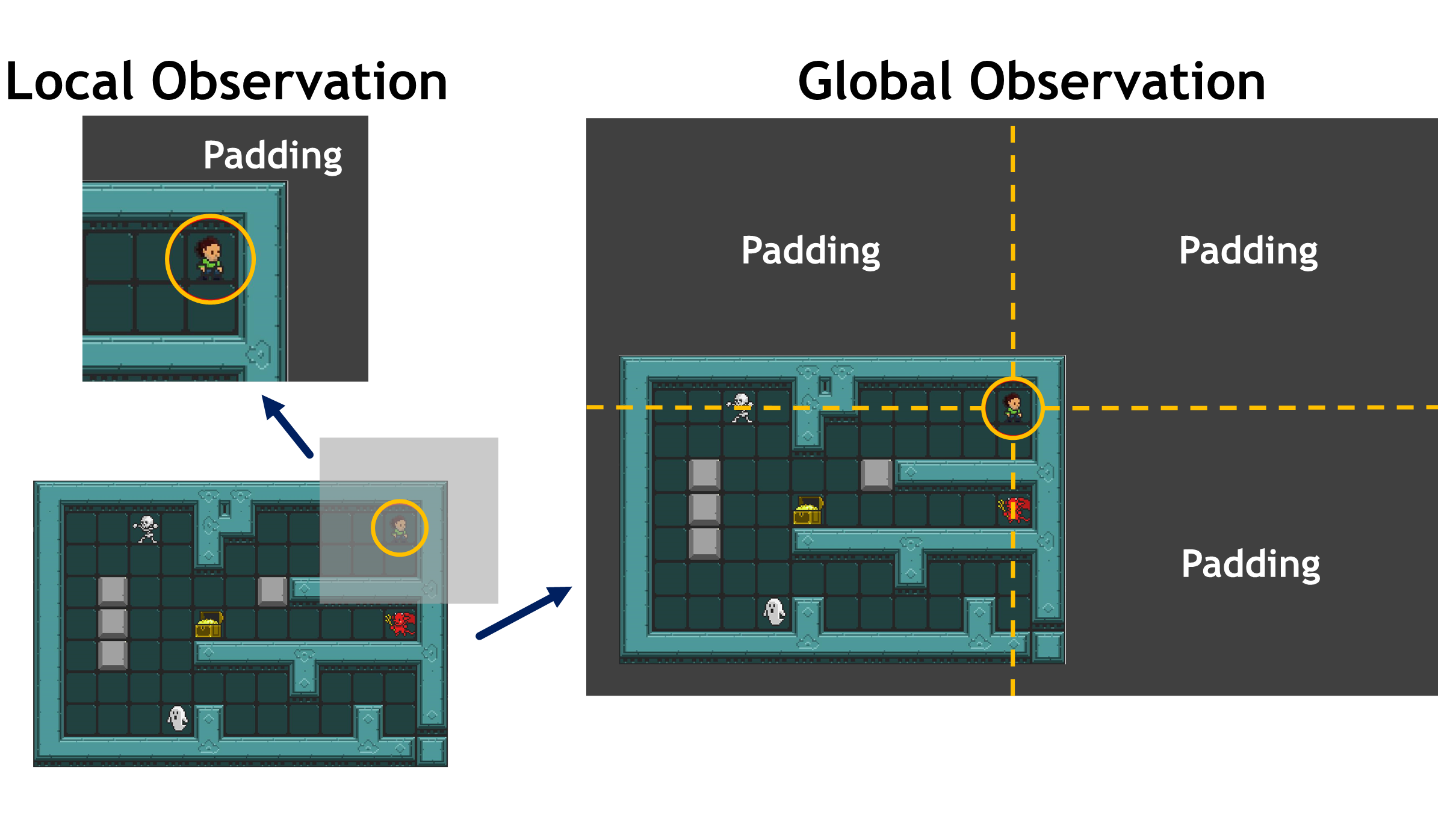
Different areas of the game observation are of different importance. The avatar's surrounding area usually has a more immediate and greater impact than the distant areas on the action selection. Therefore, Reinforcement Learning With Dual-Observation (DORL) is proposed to transform the received screenshot of the game screen into a GO and a local one. The transformation procedure is described as follows and illustrated on the right.
- A GO is not the direct use of the screenshot of the game screen. Instead, it is a \(h_g \times w_g\) RGB image in which the avatar is placed at centre, where \(h_g = 2h-h_{tile}\) and \(w_g = 2w-w_{tile}\), \(w\) and \(h\) refers to the width and height of the original screenshot, \(w_{tile}\) and \(h_{tile}\) refer to the width and height of one single tile, respectively. This guarantees that the original game screen is always contained in the global observation wherever the avatar moves.
- A LO is a \(h_l \times w_l\) RGB image (\(h_l\lt w\), \(h_l\lt h\)) in which the avatar is centred. In our experiments, \(h_l\) and \(w_l\) are set as \(50\), which means \(5 \times 5\) surrounding tiles are used.
Tile-Vector Encoded Inputs
The GVGAI platform represents levels with tile-based maps. Those tiles, either for different types of sprites or for accessible areas, have a predefined, fixed size of 10 × 10 [17]. Hence, we convert the RGB images into tile-based matrices as input, on which one-hot encoding can be easily applied. All distinct tiles appeared in the training levels have been collected to build a tile dictionary, which is a set of \(\langle\)code, reference vector \(\rangle\) tuples. The \(code \in \mathbf{N}\) identifies a unique \(10 \times 10\)-pixel tile image. For each tile, 5 pixels are selected from its \(4^{th}\) row with a stride of \(2\), and another 5 are selected from its \(5^{th}\) column with a stride of \(2\). For each selected \(10\) pixels, its averaged RGB value is calculated as \(\frac{1}{3}(v_R+v_G+v_B)\), where \(v_R\), \(v_G\) and \(v_B\) refer to the red, green and blue values of the pixel, respectively. As a result, a reference vector composed of \(10\) averaged RGB values is obtained. At every game tick during training or testing, the two RGB images of transformed global and local observations are considered as \(\frac{h_g}{10} \times \frac{w_g}{10}\) and \(\frac{h_l}{10} \times \frac{w_l}{10}\) grids of tiles, respectively. The blank spaces added during transformation, which are not part of the game screen, are replaced by zeros. For both grids, we can easily calculate the corresponding RGB-value vector for every tile inside and find its closest reference vector in the dictionary, measured by the Manhattan distance. Assuming that some unexpected tiles may appear in the test levels, we find the closest tile with distance between reference vectors instead of simply finding the code with the same reference vector. Then, the tile-based grids are converted to two matrices of tile codes, i.e., integers. Finally, one-hot encoding is applied. Since there are no more than \(16\) tile types in each game, the size of final matrix is \(\frac{h_g}{10} \times \frac{w_g}{10} \times 16\) for the transformed global observation and \(\frac{h_l}{10} \times \frac{w_l}{10} \times 16\) for the local one.
Reinforcement Learning With Dual-Observation Demo
Click button Next Step to see how the agent plays the game step by step.
Click button Auto Play to see how the agent plays the game automatically.